We migrated shields.io to Heroku just over a year ago. Heroku is a great platform but through the process of running a high-traffic application (on a busy day we serve ~30 million requests) I've got to know some of the idiosyncrasies of the platform. In this post I will run through a few of the esoteric details that have surprised me along the way as I've discovered them.
📅 Daily Restarts
Heroku's dyno manager restarts or cycles your dynos once per day. This behaviour is non-configurable. With the default settings, these daily restarts may also lead to a bit of downtime due to Heroku's default dyno lifecycle, which leads us to..
🔛 Preboot
A surprising default behaviour of Heroku is that when you deploy or restart (or Heroku restarts your dyno for you), Heroku stops the existing set of web dynos before starting the new ones. Turning on the preboot feature means Heroku will ensure the new dynos are receiving traffic before shutting down the old ones.
heroku features:enable preboot -a <myapp>
💥 Crash Restart Policy
Sometimes bugs hit production. In the case that your application crashes, for whatever reason, Heroku will automatically restart the dyno for you but it implements a backoff policy. In some cases this can lead to a situation where some of your dynos are spending over 5 hours not serving any traffic because they are in a cool-off period instead of recovering immediately. If this happens, the Heroku web UI will report you are running N dynos even when less than N of them are able to actively serve traffic because some are in a cool-off period waiting to start. Running
does tell you which dynos are up and which (if any) are crashed. This brings us on to the next point..
👑 The CLI is King
If you're planning on working with Heroku in any depth, you need to get familiar with the CLI. There are certain operations which can be performed via the CLI or API which just aren't available via the Web UI or where the CLI allows you to see more detailed information than the Web UI can show you. Fortunately Heroku's CLI app is very high quality. The --help is very discoverable and it includes examples as well as a reference. This makes it really easy to just jump in and work things out as you go.
I've already hinted at heroku features earlier in the post, but there are a variety of useful flags which can be listed with
heroku features -a <myapp> # stable
heroku labs -a <myapp> # experemental
Many of these also can't be enabled/disabled via the Web UI.
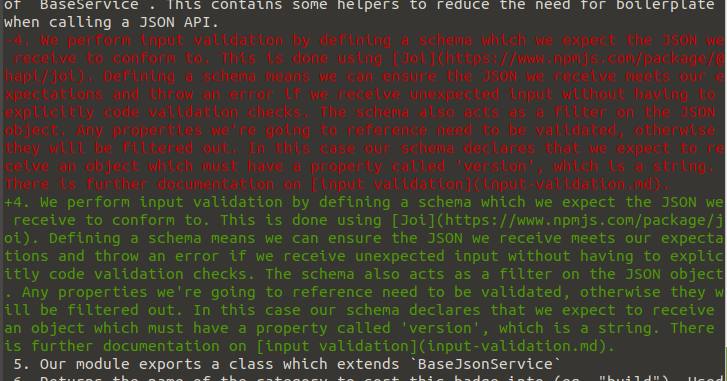 Thanks git, but what actually changed?
Thanks git, but what actually changed?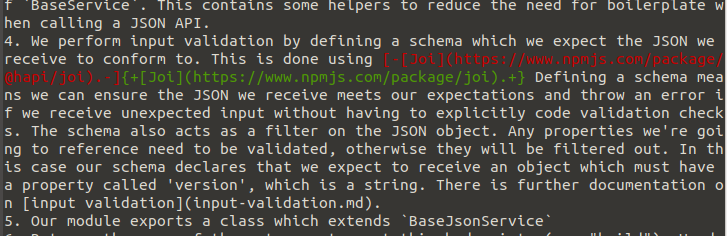 Aah that's better!
Aah that's better!